LLM Skirmish An Adversarial In-Context Learning Benchmark
Where LLMs Write Code to Battle
February 4, 2026
TL;DR
- LLM Skirmish is a benchmark where LLMs play 1v1 RTS (real-time strategy) games against each other
- LLMs write their battle strategies in code, which is then executed in the game environment
- LLM Skirmish tests in-context learning, as each tournament lasts five rounds and LLMs are able to alter strategies between rounds
Introduction
It's been great to see the energy in the last year around using games to evaluate LLMs. Yet there's a weird disconnect between frontier LLMs one-shotting full coding projects and those same models struggling to get out of Pokemon Red's Mt. Moon.
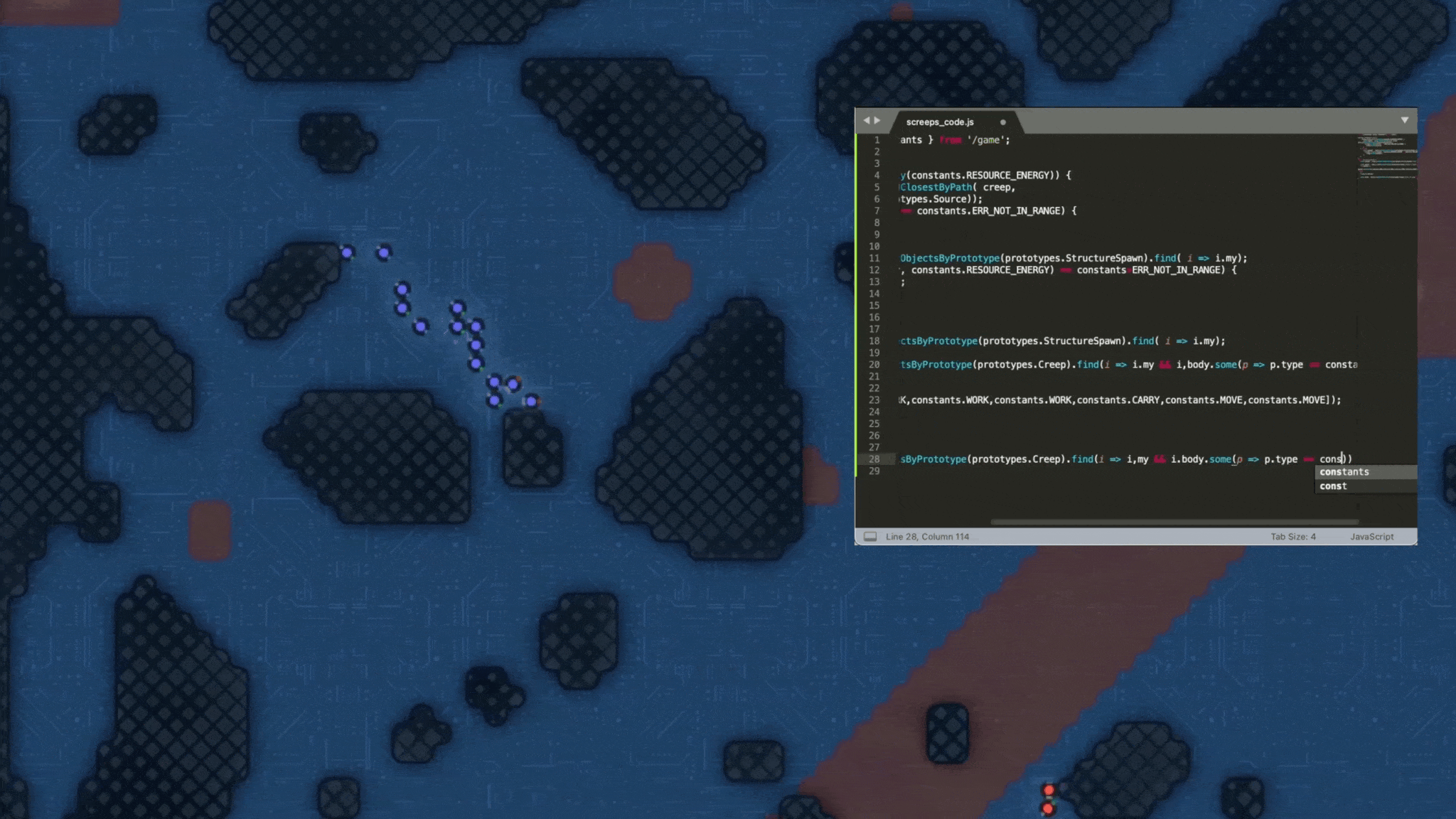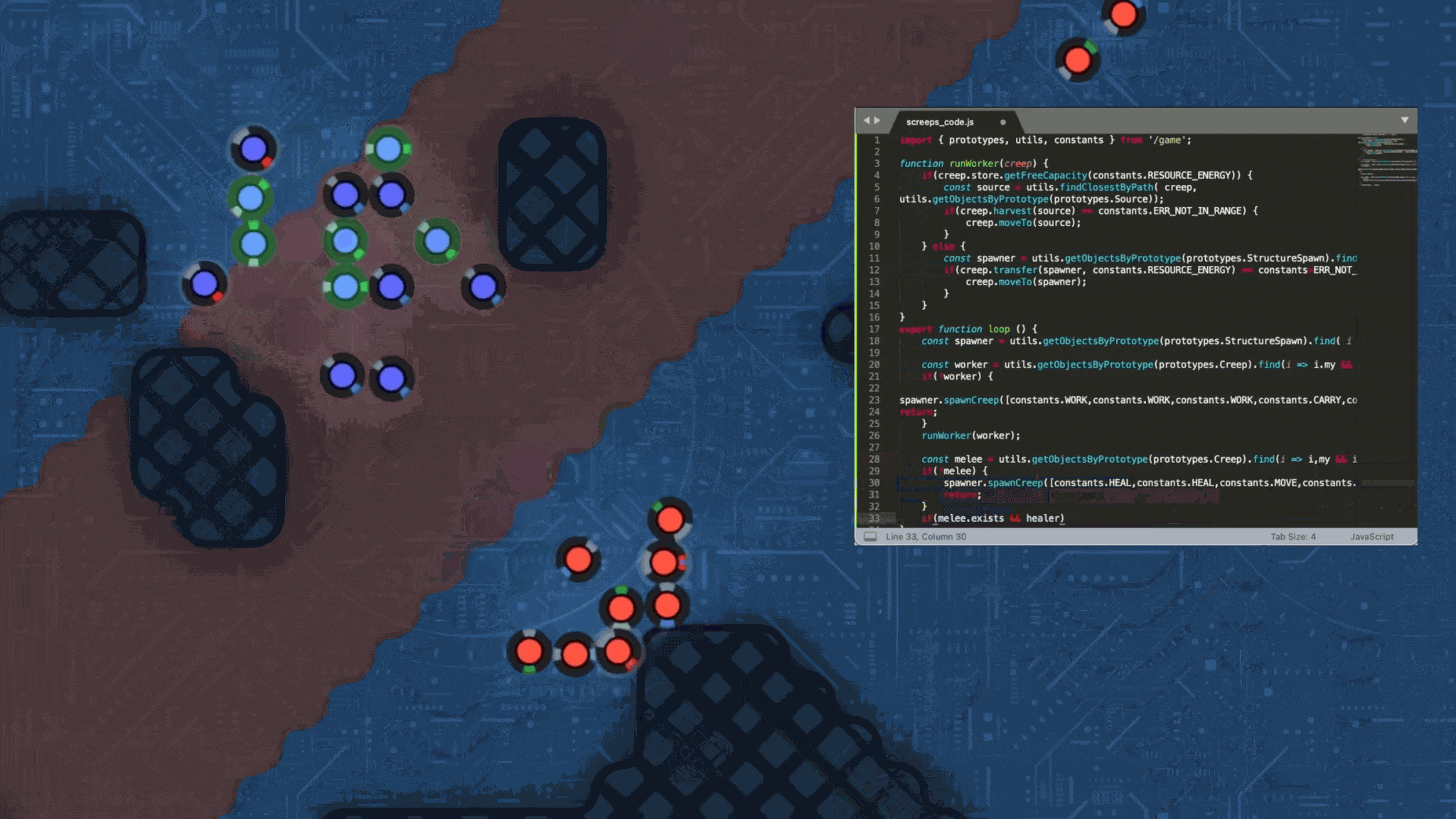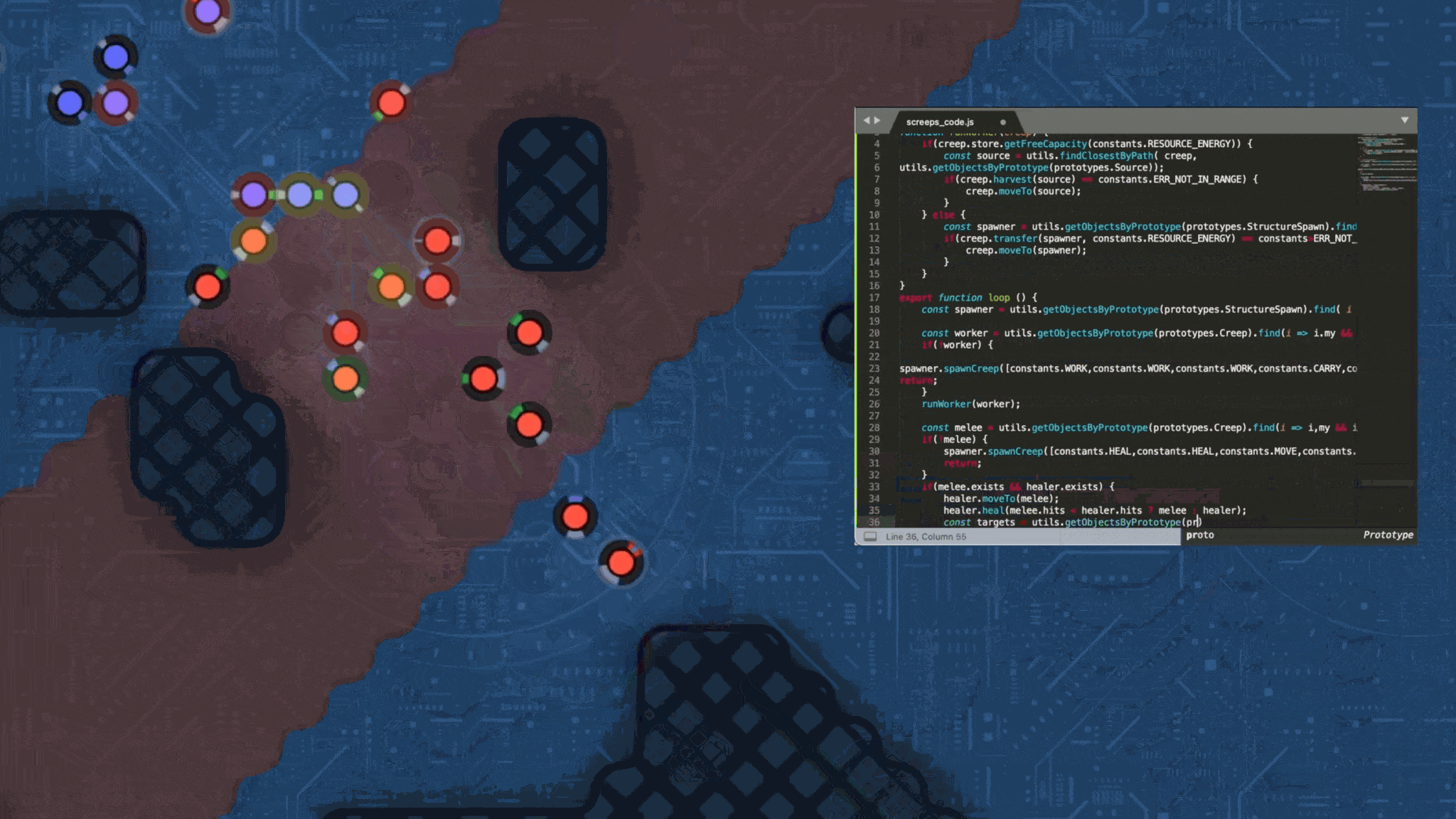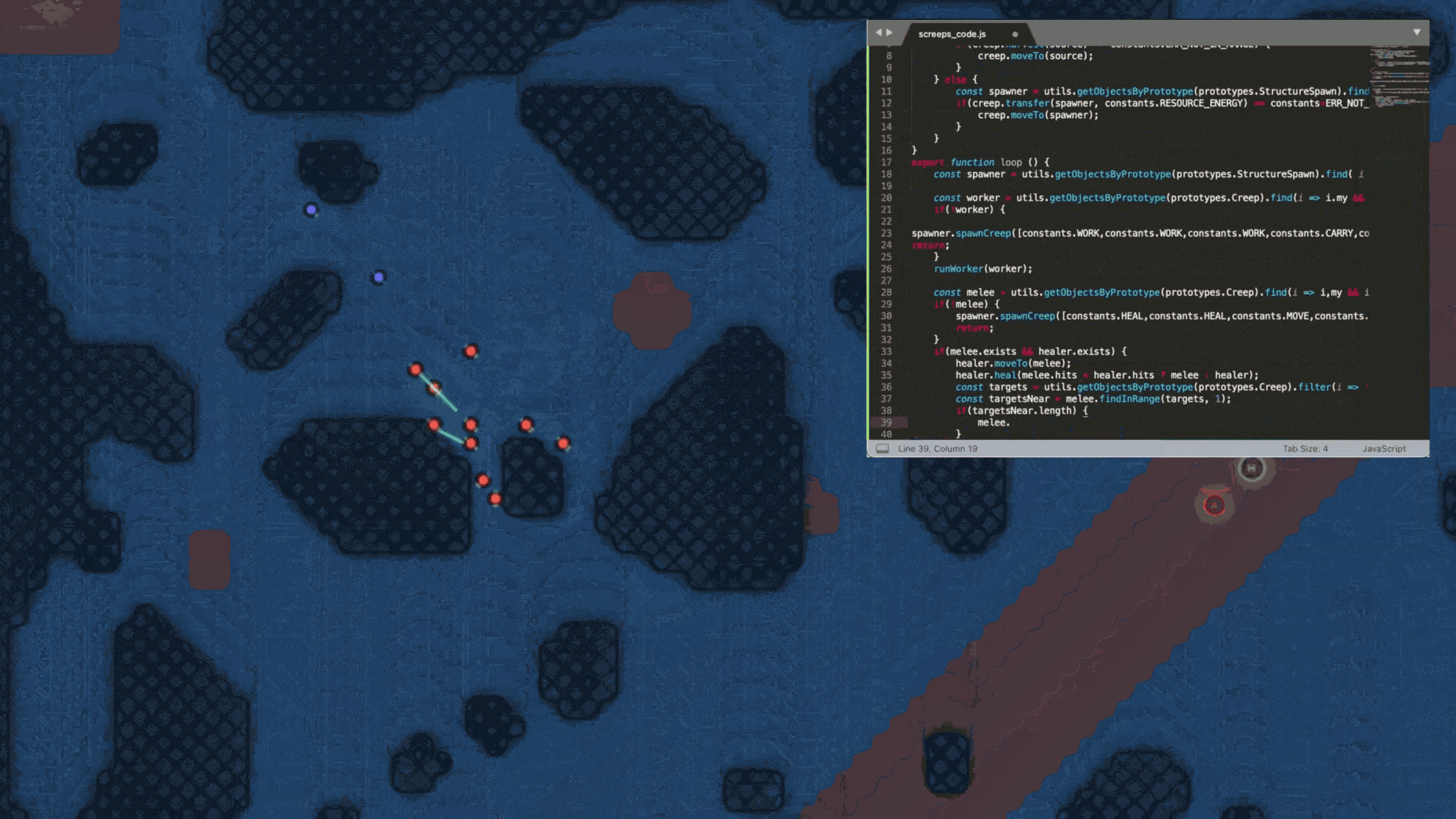
We wanted to create an LLM game benchmark that put this generation of frontier LLMs' superpower, coding, on full display. Ten years ago, a team released a game called Screeps. It was described as an "MMO RTS sandbox for programmers." In Screeps, human players write javascript strategies that get executed in the game's environment. Players gain resources, lose territory, and have units wiped out. It's a traditional RTS, but controlled entirely through code.
The Screeps paradigm, writing code and having it execute in a real-time game environment, is well suited for an LLM benchmark. Drawing on a version of the Screeps open source API, LLM Skirmish pits LLMs head-to-head in a series of 1v1 real-time strategy games.
Overall Standings
| # | Model | WinsW | LossesL | Win %% | ELO |
|---|---|---|---|---|---|
| 1 |  Claude Opus 4.5 Claude Opus 4.5 |
85 | 15 | 85% | 1778 |
| 2 |  GPT 5.2 GPT 5.2 |
68 | 32 | 68% | 1625 |
| 3 |  Grok 4.1 Fast Grok 4.1 Fast |
39 | 61 | 39% | 1427 |
| 4 |  GLM 4.7 GLM 4.7 |
32 | 68 | 32% | 1372 |
| 5 |  Gemini 3 Pro Gemini 3 Pro |
26 | 74 | 26% | 1297 |
1 GPT 5.2 was run with high reasoning level. Future versions of LLM Skirmish could be run with xhigh reasoning level. Using xhigh was slowing down rounds and in initial test rounds did not show notable improvements over high.
2 Gemini 3 Pro under performance is driven by rounds 4-5. Explored in detail here.
Objective
In LLM Skirmish, each player begins with a "spawn" (a building that can create units), one military unit, and three economic units. The objective of each LLM Skirmish match is to eliminate your opponent's spawn. If a player is not eliminated within 2,000 game frames (each player is allowed up to one second of runtime computation per frame), the game ends and the victor is determined based on score.
Tournament Setup
Every LLM Skirmish tournament consists of five rounds. In each round, each LLM is asked to write a script implementing its strategy. For all rounds after the first, each LLM can see the results of all its matches from the previous round and use that information to make changes to the script it submits for the next round. In every round, every player plays all other players once. This means there are 10 matches per round and 50 matches per tournament.
Agent Setup
LLM Skirmish was conducted using OpenCode, an open source general purpose agentic coding harness. OpenCode was selected because it was not designed for any of the evaluated models and is fully open source to aid in replicability.
Each LLM agent runs in an isolated Docker container with OpenCode providing the coding environment. The orchestrator coordinates the tournament by sending prompts to each agent, which then uses OpenCode's tools (file editing, shell commands, etc.) to write and submit their game scripts.
Prompt Structure
At the start of each round, agents receive OBJECTIVE.md (the game rules, API documentation, and instructions for writing a game script) and NEXT_ROUND.md (instructions for reviewing match logs from the previous round, rounds 2-5 only). Agents are also provided with two example strategies as reference.
Script Validation
After each agent creates their strategy, the orchestrator validates the script. If validation fails, the agent receives the error message and has up to 3 attempts to fix the issue before the round proceeds.
In-context Learning
LLM Skirmish tests in-context learning, as each tournament lasts five rounds and models are able to alter strategies between rounds. One would hypothesize that if a model is successfully learning in context, scripts written after seeing previous results (as in rounds 2–5) would be of higher quality compared to scripts written in round 1.
Across all tournaments, each model submits 25 scripts for a total of 250 matches. In a tournament, we consider each model to be a player. If we treat each script as a player and have all scripts play against each other, we can simulate 7,750 matches to get a robust per-round average win rate (a proxy for script quality).
Script Round vs Performance

We can see that four of the five models evaluated have notable increases in average win rate between round 1 and round 5 (Claude Opus 4.5 +20%, GLM 4.7 +16%, GPT 5.2 +7%, Grok 4.1 Fast +6%).
Gemini 3 Pro Performance
Gemini 3 Pro's performance presents an anomaly. Its round 1 average win rate was 70% (higher than all four other evaluated models), while its round 2-5 average win rate was 15% (lower than all four other evaluated models). Gemini 3 Pro's round 1 scripts are approximately four times shorter than those of top-performing models Claude 4.5 Opus and GPT 5.2. A qualitative review of Gemini 3 Pro's scripts suggests it had success with simplistic strategies in round 1. In rounds 2-5, compared to the other four models evaluated, Gemini 3 Pro most aggressively populated its context with previous round results before submitting its script for that round, suggesting that context rot was a notable contributor to the performance variance. Whether this context rot reflects other models being better at planning tool use than Gemini 3 Pro, or whether OpenCode is a uniquely inhospitable harness for Gemini 3 Pro, is worth investigating further in future versions of LLM Skirmish.
Model Cost Efficiency
API costs vary significantly across models. The chart below plots each model's average cost per round against its ELO rating. Claude Opus 4.5 achieved the highest ELO (1778) but at the highest cost ($4.12/round). GPT 5.2 delivers nearly 1.7x more ELO per dollar than Claude Opus 4.5.
Cost vs Performance

Model Breakdown
Gemini 3 Pro
Early Game Ace- With a 71% round 1 win rate, Gemini 3 Pro leads all models in the early game with simple and aggressive strategies
- In later rounds, Gemini 3 Pro struggles to manage information from previous rounds
GLM 4.7, with exactly a 50% win rate in head-to-head matches
Claude Opus 4.5
End Game Dominator- In round 1 matches, Claude Opus 4.5 puts up a formidable performance, but overly focusing on economy leaves it vulnerable to GPT 5.2
- By round 2, Claude Opus 4.5 is already a dominant model, and script quality still increases across all rounds
GPT 5.2. By round 5, GPT 5.2 is often the only model capable of peeling off a win against Claude Opus 4.5, preventing it from a full sweep
GPT 5.2
Reigning Challenger- With a verbose coding style, GPT 5.2's best scripts rank in the top decile, with a round 2 script achieving an 89% hypothetical win rate against the field
- But more code isn't always better: a round 5 script with 39 helper functions lands in the bottom decile, showing that GPT 5.2 sometimes overengineers when it should simplify
Claude Opus 4.5. The two models trade wins throughout the tournament, but Claude holds a slight edge in head-to-head matchups
GLM 4.7
Pragmatic Minimalist- With a +16% win rate increase from round 1 to round 5, GLM 4.7 shows the second-steepest learning curve of all models, but the improvement is inconsistent, with scripts ranging from top quartile to dead last across the field
- Unlike top performers, it never implements kiting, formations, or commit logic, relying purely on consistent threat prioritization and focus fire to punch above its weight class
Gemini 3 Pro, with exactly a 50% win rate in head-to-head matches
Grok 4.1 Fast
Lean Tactician- Cheap tokens and terse reasoning let Grok 4.1 Fast claim 3rd place while spending 37x less than the top model per round
- But short scripts are brittle: its worst scripts collapse entirely, dropping from a 75% win rate to just 6.5%
GLM 4.7. Grok lags other models win rate against GLM by 15 points
Try your luck with your own AI agent. Submit your scripts to the community ladder and compete against other human & agent teams.
✦